얼마 전에 흥미로운 논문을 보게 되었다. https://arxiv.org/abs/1703.03994
논문의 제목은 이 글의 제목과 같은데, 간단히 요약하자면 컨트랙트를 코딩하고 EVM에서 동작하도록 컴파일 될 때 개스 사용이 최적화 되지 않고 있다는 이야기다. 즉, 코딩을 어떻게 하느냐에 따라 개스 소모가 달라지고, 이런 부분은 실제 Solidity로 개발을 하는 개발자는 확인을 하기가 어려우니 컴파일러의 최적화 기능을 강화해야 한다라는 것이다. 5페이지짜리 짧은 페이퍼이고, 매우 Plain English로 쓰여 있으니 부담없이 읽을 만 하다.
Ethereum의 스마트 컨트랙트에 친숙하지 않은 분을 위해 약간의 부연 설명을 하자면, Ethereum에서는 스마트 컨트랙트를 (현재) Solidity로 작성하며, 이는 컴파일되어 EVM(Ethereum Virtual Machine)코드로 변환된다. 실행 시 컨트랙트는 Miner의 EVM에서 동작하게 되며, 이 때 gas를 사용하게 된다. 즉, 누군가의 컴퓨팅 자원을 사용하니 댓가를 지불해야 한다는 것으로 쉽게 이해할 수 있겠다.
또한 gas는 DoS 어택을 막는 용도로도 중요한 역할을 한다. 간단히 예를 들어 컨트랙트에 무한 루프를 넣고 무거운 동작을 반복하게 만든다면 노드의 실행에 장애가 생길 수 있는데, 각 Operation에 비용을 지불하게 함으로써 이러한 공격을 막게 된다. (만약 해커가 만수르라면??)
EVM의 동작에는 소모되는 gas가 설정되어 있는데, 이는 Yellow Paper의 Appendix G에서 확인할 수 있다. 해당 표는 아래와 같다.

대충 살펴 보면 굉장히 싼 오퍼레이션이 있는 반면에, 매우 비싼 것들이 존재한다. 대개 스토리지를 사용하거나, 계정을 생성하는 것들이 그렇다. 그렇다면 개발할 때에도 가급적 gas를 적게 사용하도록 만들어야 할 것이다. (버튼 한번 누를 때마다 1,000원씩 날아간다면 무서워서 쓰겠나..)
다시 논문의 내용으로 돌아오면, 저자들은 2가지 분류의 7가지 정도의 개스를 낭비하는 패턴을 찾아 냈다. 그리고 이런 부분은, EVM의 동작을 깊이 이해하지 못하는 개발자들이 파악하기 어렵기 때문에 컴파일러에서 처리를 해 주어야 한다고 이야기 하고 있다.
첫 번째 분류인 Useless Code에서는 두 가지 패턴을 이야기 하고 있는데, dead code와 opaque predicate이다.

어찌 보면 이 부분은 간단하다. 왼쪽의 패턴 1에서는 4행의 코드는 실행될 일이 없다. x는 5보다 크기 때문에, 이 값을 제곱한 값이 20보다 작을 일은 없기 때문이다. 우측 패턴의 경우는 불필요한 조건문이 들어간 경우다. 3행은 의미가 없다. 하지만 gas를 사용한다.
두 번째 분류는 Loop Related Patterns인데, 이는 좀 더 심각하다. 말 그대로 루프를 통해 반복되기 때문에 불필요한 비용 낭비가 급격히 올라갈 수 있기 때문이다.
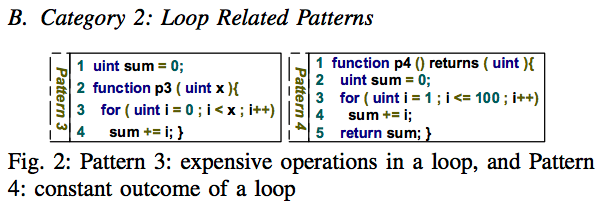
패턴 3은 비싼 오퍼레이션이 루프에 들어가 있는 경우다. sum은 스토리지에 보관되는 변수인데, SLOAD를 통해 스택에 올라가고, SSTORE를 통해 값을 저장한다. SLOAD는 200 gas를, SSTORE는 20,000 gas(!)를 사용한다. 값 비싼 오퍼레이션은 루프 밖으로 빼야 하고, 임시적으로 사용되는 값들은 memory 를 사용하는 편이 싸게 먹힌다.
패턴 4는 루프의 결과가 항상 상수가 나오는 경우다. 3,4행의 결과로 sum은 항상 5050이 된다. 즉 return sum; 보다는 return 5050; 으로 하고 루프를 없애는게 낫다.

패턴 5는 동일한 역할을 하는 루프라면 루프를 합치라는 이야기다. 4,6행에서 시작하는 두 개의 루프는 동일한 횟수만큼 반복하는데, 하나의 루프로 합쳐서 오퍼레이션의 수와 bytecode 사이즈를 줄이라는 이야기다.
패턴6은 반복되는 연산을 빼라는 것이다. 6행에 보면 sum + x + y가 있는데, 여기서 x + y는 루프 안에 있을 필요가 없다. x + y를 반복 계산하기 위해 SLOAD가 반복 호출되는 결과를 가져 온다.

패턴 7은 비교문의 결과를 컴파일 시에 알 수는 없지만, 루프 내에서 항상 동일한 결과를 가질 경우 루프 바깥으로 빼라는 것이다. 3행의 x > 0 는, x 값에 따라 참 또는 거짓이겠지만 루프를 반복할 대 항상 동일한 값을 가지게 된다. 이런 경우 루프를 들어가기 전에 미리 조건을 검사하는 것이 유리하다.
사실 이러한 패턴들은 어찌 보면 상당히 사소한 것들처럼 보이고, 누가 저렇게 할까 싶은 것도 있기는 하다. 하지만 사소하기 때문에 의외의 엄청난 결과를 가져올 위험성도 내포하고 있다.
저자들은 GASPER라는 툴을 만들어 2016년 11월 5일 까지 Ethereum 네트워크에 등록된 모든 컨트랙트를 전수 검사를 했다. 전체 수는 566,907이지만 코드가 없는 것, 중복된 것 등을 모두 제외한 4,669 컨트랙트를 대상으로 실시했는데 상당히 놀라운 결과가 나왔다.
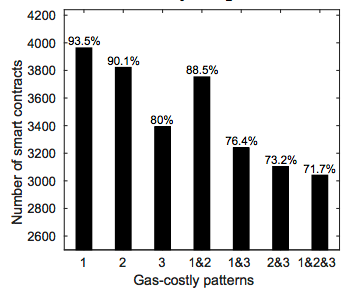
패턴 1, 2 (불필요한 코드)가 전체 컨트랙트의 93.5%, 90.1% 에서 발견되었고, 루프 내부에 비싼 오퍼레이션을 포함하는 경우도 전체의 80%에 달했다. 이 세 가지 모두를 포함하고 있는 경우는 71.7%.
즉 이런 낭비를 만드는 것이 매우 쉽다는 것을 의미하는 결과라고 본다. 특히, 그 동안 서버의 스펙이 높아져 가면서 사실 코드 자체의 최적화에 대한 고민은 상대적으로 덜 중요해져 왔다고 생각하는데, Solidity로 개발할 때는 (최소한 당분간은) 주의가 필요하다.
특히 아직 표준 라이브러리가 명확하게 구성되어 있지 않고, 데이터의 보관을 외부 DB등에 사요하는 것에 익숙해져 있는 경우가 많은데 Solidity에서는 사용 불가능하기 때문에 이런 낭비에 대해 좀 더 고민할 필요가 있다고 하겠다.
마지막으로 http://dapps.ethercasts.com/ 을 살펴 보다가 발견한 것인데, 아마도 베트남 사람으로 보이는 친구가 출/퇴근 펀치 카드를 간단히 구현한 것이 있었다. 재미 있는 것은 개략적인 사용료인데, gas price = 0.00000002 Ether, 1 Ether = $40으로 가정했을 때의 월 사용료가 $343.2에 달한다는 것이다. (관리자 10명, 직원 100명, 직원은 하루에 두 번 카드를 체킹한다는 가정)
아직은 막 시작된 분야이기 때문에 비즈니스 모델을 고민하기에 이른 감이 없지 않지만, 저렇게 비싼 비용을 지불하고라도 사용할만한 이익을 제공하기가 쉽지는 않아 보인다.
